Welcome to Part II of Causal Inference Book


11.1 Data cannot speak for themselves
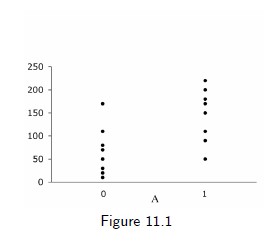
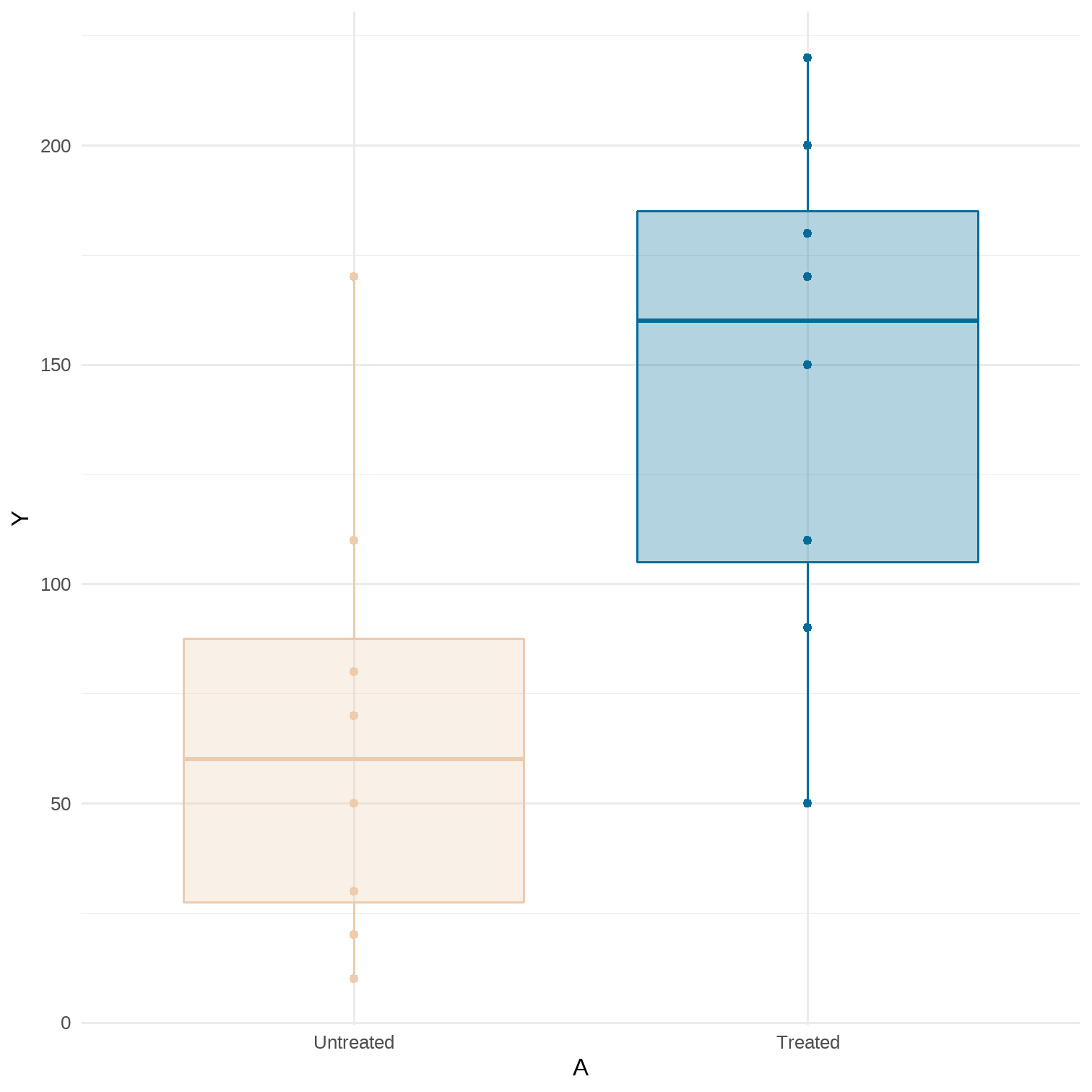
Population mean in the treated is the sample average 146.25 for those with
Population mean in the untreated is the sample average 67.50 for those with
Under exchangeability between and , the average treatment effect (ATE) is
11.1 Data cannot speak for themselves
library(tidyverse)library(magrittr)# Sample averages by treatment level# Data for Figure 11.1A <- c(1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0)Y <- c(200, 150, 220, 110, 50, 180, 90, 170, 170, 30, 70, 110, 80, 50, 10, 20)data <- tibble(A, Y) %>% mutate(A = factor(A, levels = c("0", "1"), labels = c("Untreated", "Treated")))p <- data %>% ggplot(aes(x = A, y = Y, color = A, fill = A)) + geom_point() + geom_boxplot(alpha = 0.3) + theme_minimal() + theme(legend.position = "none") + scale_color_manual(values = wesanderson::wes_palette(name = "Darjeeling2", n = 2)) + scale_fill_manual(values = wesanderson::wes_palette(name = "Darjeeling2", n = 2))data %>% group_by(A) %>% summarise(mean = mean(Y)) %>% kableExtra::kable()| A | mean |
|---|---|
| Untreated | 67.50 |
| Treated | 146.25 |
11.1 Data cannot speak for themselves
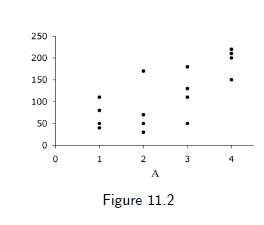
A is polytomous variable
- no treatment (A = 1)
- low-dose treatment (A = 2)
- medium-dose treatment (A = 3)
- high-dose treatment (A = 4)
Probability of getting any treatment level is 0.25
11.1 Data cannot speak for themselves
# Sample averages by treatment level# Data for Figure 11.2A <- c(1, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3, 4, 4, 4, 4)Y <- c(110, 80, 50, 40, 170, 30, 70, 50, 110, 50, 180, 130, 200, 150, 220, 210)data <- tibble(A, Y) %>% mutate(A = factor(A))p <- data %>% ggplot(aes(x = A, y = Y, color = A, fill = A)) + geom_point() + geom_boxplot(alpha = 0.3) + theme_minimal() + theme(legend.position = "none") + scale_color_manual(values = wesanderson::wes_palette(name = "Darjeeling1", n = 4)) + scale_fill_manual(values = wesanderson::wes_palette(name = "Darjeeling1", n = 4))data %>% group_by(A) %>% summarise(mean = mean(Y)) %>% kableExtra::kable()| A | mean |
|---|---|
| 1 | 70.0 |
| 2 | 80.0 |
| 3 | 117.5 |
| 4 | 195.0 |
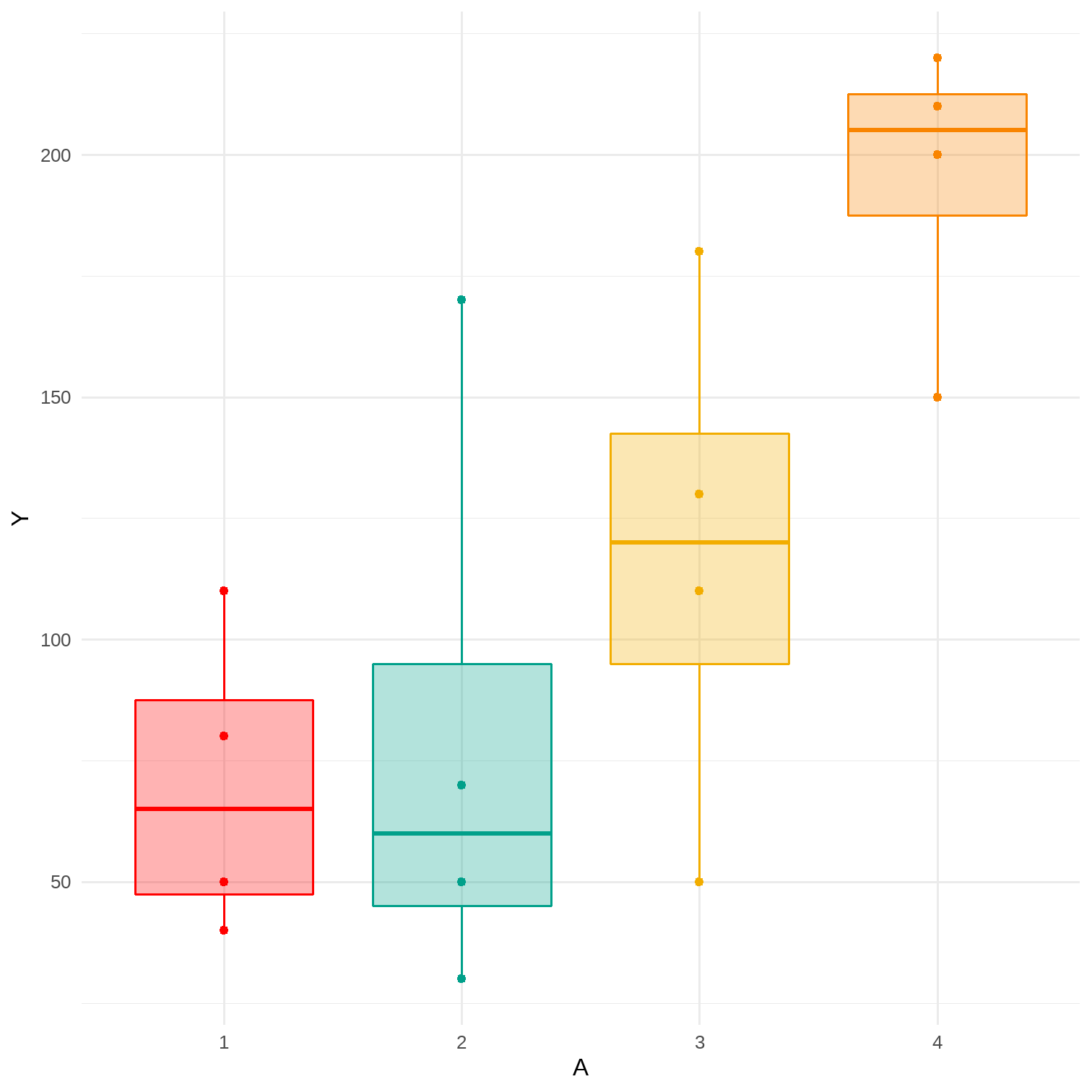
11.1 Data cannot speak for themselves
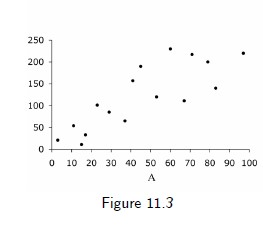
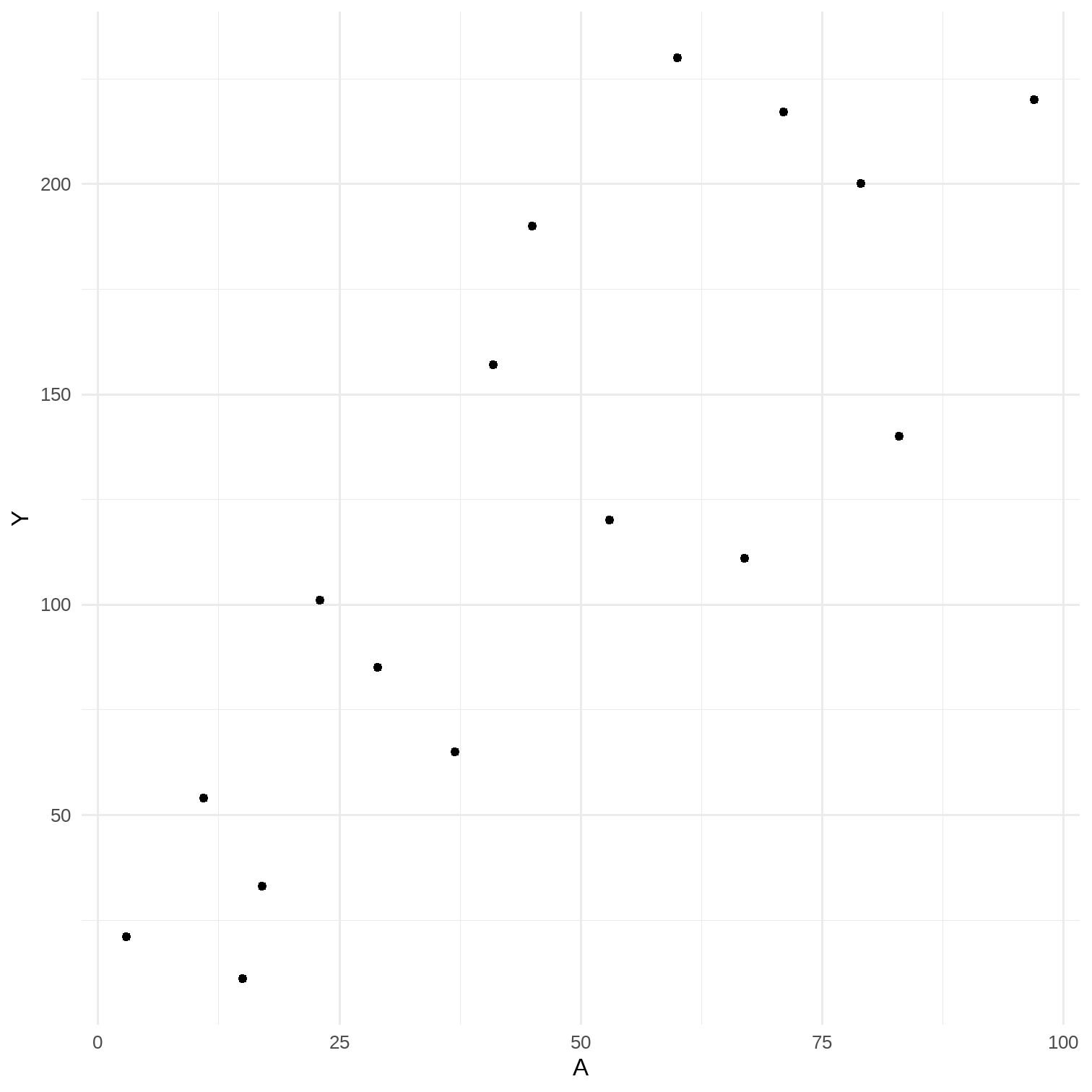
- A is a dose treatment in in mg/day
- Values [0;100]
- A continuous variable is a categorical variable with infinite number of categories
- estimate, in the target population, the mean of the outcome Y among individuals with treatment level A = 90
11.1 Data cannot speak for themselves
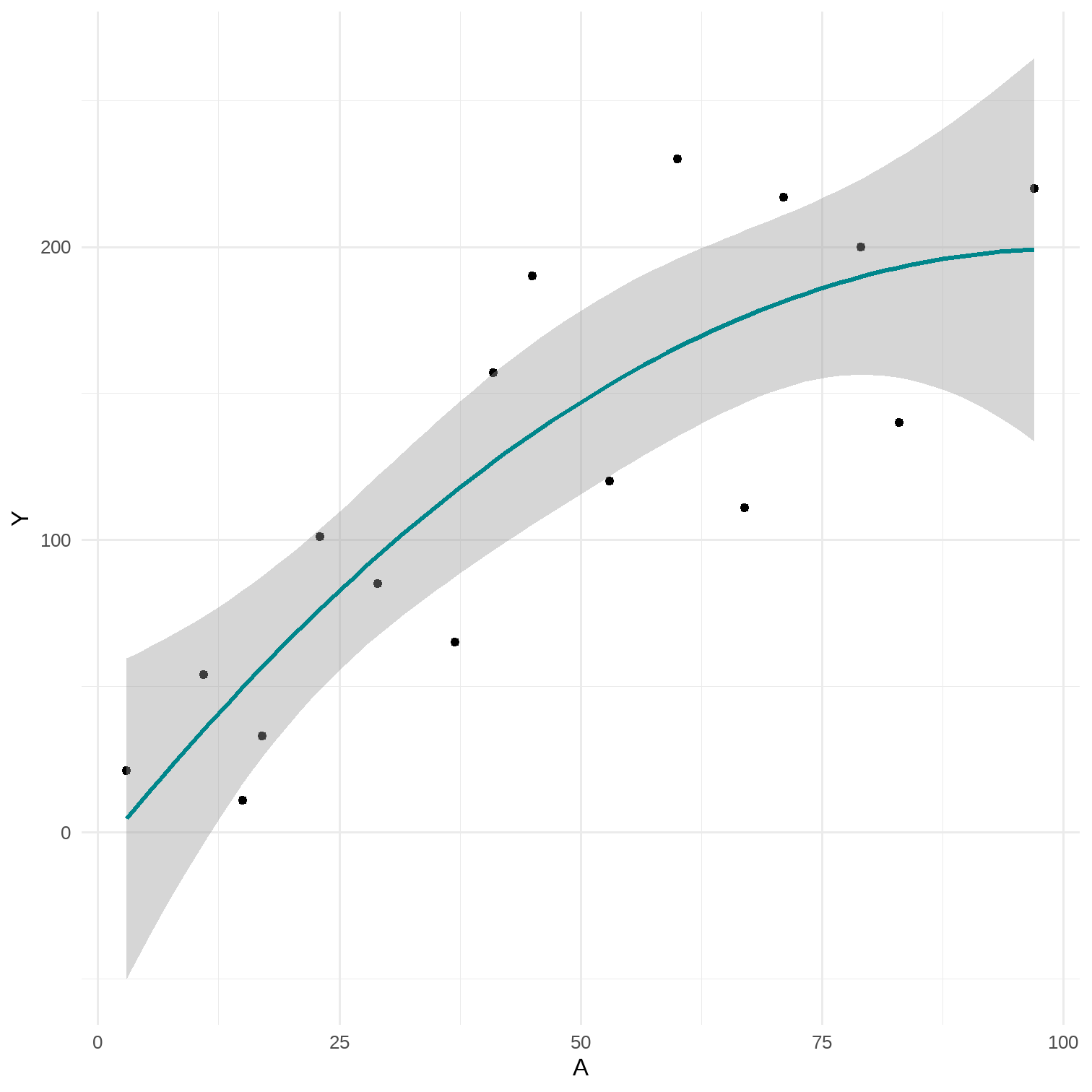
# 2-parameter linear model# Data for Figures 11.3A <- c(3, 11, 17, 23, 29, 37, 41, 53, 67, 79, 83, 97, 60, 71, 15, 45)Y <- c(21, 54, 33, 101, 85, 65, 157, 120, 111, 200, 140, 220, 230, 217, 11, 190)data <- tibble(A, Y)rm(A, Y)res_lm <- lm(Y ~ A, data = data) %>% broom::tidy(., conf.int = T) %>% select(1, 2, 6, 7)p <- data %>% ggplot(aes(x = A, y = Y)) + geom_point() + theme_minimal()## # A tibble: 2 x 4## term estimate conf.low conf.high## <chr> <dbl> <dbl> <dbl>## 1 (Intercept) 24.5 -21.2 70.3 ## 2 A 2.14 1.28 2.99
# Figure 11.4p <- data %>% ggplot(aes(x = A, y = Y)) + geom_point() + geom_smooth(method = lm, color = "#00868B") + theme_minimal()p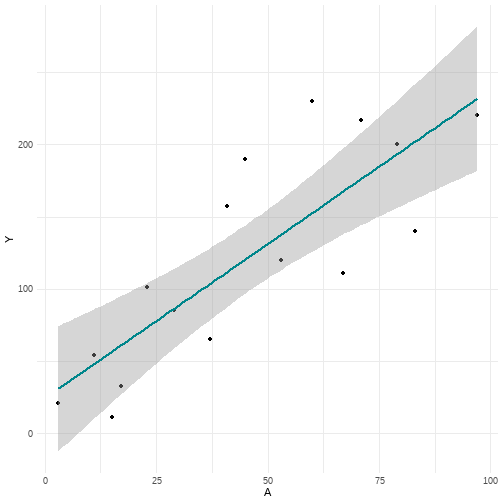
lm(Y ~ A, data = data) %>% broom::tidy(., conf.int = T) %>% select(1, 2, 6, 7)## # A tibble: 2 x 4## term estimate conf.low conf.high## <chr> <dbl> <dbl> <dbl>## 1 (Intercept) 24.5 -21.2 70.3 ## 2 A 2.14 1.28 2.9924.546369 + 2.137152*90## [1] 216.8911.4 Smoothing
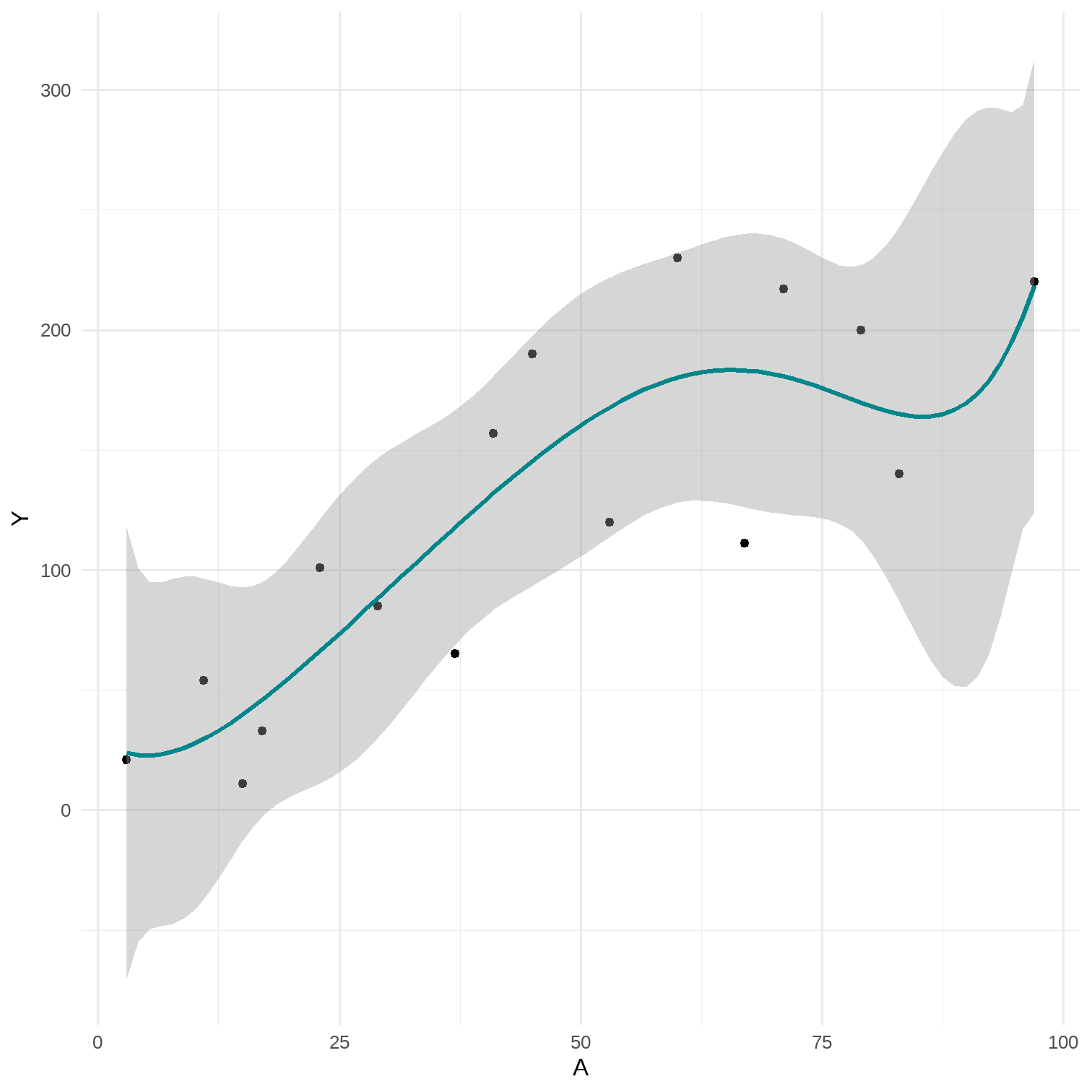
data %<>% mutate(A_sq = A*A)lm(Y ~ A + A_sq, data = data) %>% broom::tidy(., conf.int = T) %>% select(1, 2, 6, 7)## # A tibble: 3 x 4## term estimate conf.low conf.high## <chr> <dbl> <dbl> <dbl>## 1 (Intercept) -7.41 -76.0 61.2 ## 2 A 4.11 0.800 7.41 ## 3 A_sq -0.0204 -0.0535 0.0127# predict by hand-7.40687745 + 4.10722663*90 -0.02038477*90^2## [1] 197.1269# 3 parametersp <- data %>% ggplot(aes(x = A, y = Y)) + geom_point() + theme_minimal() + stat_smooth(method = "glm", formula = y ~ poly(x, 2), color = "#00868B")# 7 parametersp2 <- data %>% ggplot(aes(x = A, y = Y)) + geom_point() + theme_minimal() + stat_smooth(method = "glm", formula = y ~ poly(x, 6), color = "#00868B")